
概述
VoxCPM 是一种新颖的无分词器文本转语音 (TTS) 系统,它重新定义了语音合成的真实感。通过在连续空间中对语音进行建模,它克服了离散标记化的局限性,并实现了两个旗舰功能:上下文感知语音生成和逼真的零样本语音克隆。
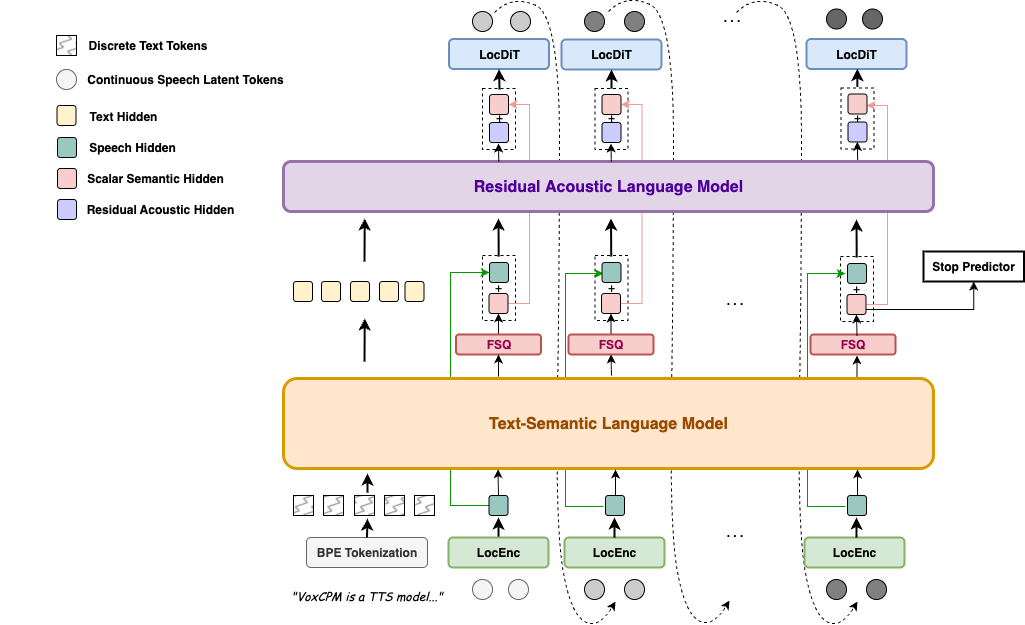
与将语音转换为离散标记的主流方法不同,VoxCPM 使用端到端扩散自回归架构,直接从文本生成连续的语音表示。它基于MiniCPM-4主干,通过分层语言建模和FSQ约束实现隐式语义-声学解耦,大大增强了表达性和生成稳定性。
🚀 主要特点
- 上下文感知、富有表现力的语音生成 – VoxCPM 理解文本以推断和生成适当的韵律,提供具有卓越表现力和自然流畅的语音。它根据内容自发地调整说话风格,在 180 万小时的海量双语语料库上训练出高度合适的声音表达。
- 逼真的语音克隆 – VoxCPM 只需一个简短的参考音频剪辑,即可执行准确的零样本语音克隆,不仅捕捉说话者的音色,还捕捉口音、情感语气、节奏和节奏等细粒度特征,以创建忠实自然的复制品。
- 高效合成 – VoxCPM 支持在消费级 NVIDIA RTX 4090 GPU 上实时因子 (RTF) 低至 0.17 的流式合成,从而实现实时应用。
快速入门
🔧 从 PyPI 安装
pip install voxcpm
1. 模型下载(可选)
默认情况下,首次运行脚本时,会自动下载模型,但您也可以提前下载模型。
- 下载 VoxCPM-0.5B
from huggingface_hub import snapshot_downloadsnapshot_download(“openbmb/VoxCPM-0.5B”)
- 下载 ZipEnhancer 和 SenseVoice-Small。我们在网络演示中使用 ZipEnhancer 来增强语音提示,并使用 SenseVoice-Small 进行语音提示 ASR。
from modelscope import snapshot_downloadsnapshot_download(‘iic/speech_zipenhancer_ans_multiloss_16k_base’)snapshot_download(‘iic/SenseVoiceSmall’)
2. 基本用法
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")
3. CLI 用法
安装后,入口点是 (或使用 )。voxcpmpython -m voxcpm.cli
# 1) Direct synthesis (single text)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." --output out.wav
# 2) Voice cloning (reference audio + transcript)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--output out.wav \
--denoise
# (Optinal) Voice cloning (reference audio + transcript file)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-file "/path/to/text-file" \
--output out.wav \
--denoise
# 3) Batch processing (one text per line)
voxcpm --input examples/input.txt --output-dir outs
# (optional) Batch + cloning
voxcpm --input examples/input.txt --output-dir outs \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--denoise
# 4) Inference parameters (quality/speed)
voxcpm --text "..." --output out.wav \
--cfg-value 2.0 --inference-timesteps 10 --normalize
# 5) Model loading
# Prefer local path
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
# Or from Hugging Face (auto download/cache)
voxcpm --text "..." --output out.wav \
--hf-model-id openbmb/VoxCPM-0.5B --cache-dir ~/.cache/huggingface --local-files-only
# 6) Denoiser control
voxcpm --text "..." --output out.wav \
--no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
# 7) Help
voxcpm --help
python -m voxcpm.cli --help
4. 开始网络演示
您可以通过运行 来启动 UI 界面,它允许您执行语音克隆和语音创建。python app.py
👩 🍳 语音厨师指南
欢迎来到 VoxCPM 厨房!按照这个食谱来制作完美的生成语音。让我们开始吧。
🥚 第 1 步:准备基础成分(内容)
首先,选择您希望如何输入文本:。
- 常规文本(经典模式)
- ✅ 保持“文本规范化”开启。自然输入(例如,“你好,世界!123″).系统将使用 WeTextProcessing 库自动处理数字、缩写和标点符号。
- 音素输入(本机模式)
- ❌ 关闭“文本规范化”。输入音素文本,如 {HH AH0 L OW1} (EN) 或 {ni3}{hao3} (ZH) 以进行精确的发音控制。在这种模式下,VoxCPM 还支持对其他复杂的非规范化文本的本机理解 – 试试吧!
🍳 第 2 步:选择您的风格配置文件(语音风格)
这是赋予您的音频独特声音的秘诀。
- 用提示演讲烹饪(遵循著名食谱)
- 提示语音为 VoxCPM 提供了所需的声学特性。演讲者的音色、说话风格,甚至背景声音和氛围都会被复制。
- 要获得干净、录音室品质的声音:
- ✅ 启用“提示语音增强”。这就像一个噪音过滤器,可以消除背景嘶嘶声和隆隆声,为您提供纯净、干净的语音克隆。
- Cooking au Naturel(让模特即兴创作)
- 如果没有提供参考,VoxCPM 就会成为创意厨师!它将根据文本本身推断出合适的说话风格,这要归功于其基础模型 MiniCPM-4 的文本智能性。
- 专业提示:用任何文本(诗歌、歌词、戏剧性独白)挑战 VoxCPM,它可能会带来一些有趣的结果!
🧂 第 3 步:最后的调味料(微调您的结果)
您已准备好服务!但对于想要调整风味的大厨来说,这里有两种关键的香料。
- CFG 值(遵循配方的程度)
- 默认:一个很好的起点。
- 声音听起来紧张或奇怪?降低此值。它告诉模型更加放松和即兴创作,非常适合富有表现力的提示。
- 需要最大程度的清晰度和对文本的遵守?稍微抬起它以使模型系在更紧的皮带上。
- 推理时间步长(煨时间:质量与速度)
- 需要快餐吗?使用较小的数字。非常适合快速草稿和实验。
- 做一顿美食?使用更高的数字。这可以让模型“炖”更长时间,细化音频以获得卓越的细节和自然度。
快乐创作!🎉 从默认设置开始,然后从那里进行调整以适合您的项目。厨房是你的!
您是否使用 VoxCPM 构建了一些很酷的东西?我们很乐意在这里介绍它!请打开问题或拉取请求以添加您的项目。
📊 性能亮点
VoxCPM 在公共零样本 TTS 基准测试中取得了有竞争力的结果:
种子-TTS-评估基准测试
| 型 | 参数 | 开源 | 测试-CN | 测试-ZH | 测试-困难 | |||
|---|---|---|---|---|---|---|---|---|
| WER/% ⬇ | SIM卡/% ⬆ | CER/% ⬇ | SIM卡/% ⬆ | CER/% ⬇ | SIM卡/% ⬆ | |||
| 兆型TTS3 | 0.5B | ❌ | 2.79 | 77.1 | 1.52 | 79.0 | – | – |
| 迪塔尔 | 0.6B | ❌ | 1.69 | 73.5 | 1.02 | 75.3 | – | – |
| 舒适的声音3 | 0.5B | ❌ | 2.02 | 71.8 | 1.16 | 78.0 | 6.08 | 75.8 |
| 舒适的声音3 | 1.5乙 | ❌ | 2.22 | 72.0 | 1.12 | 78.1 | 5.83 | 75.8 |
| 种子-TTS | – | ❌ | 2.25 | 76.2 | 1.12 | 79.6 | 7.59 | 77.6 |
| MiniMax-语音 | – | ❌ | 1.65 | 69.2 | 0.83 | 78.3 | – | – |
| 舒适之声 | 0.3B | ✅ | 4.29 | 60.9 | 3.63 | 72.3 | 11.75 | 70.9 |
| 舒适之声2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 | 6.83 | 72.4 |
| F5-TTS系统 | 0.3B | ✅ | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 |
| 火花TTS | 0.5B | ✅ | 3.14 | 57.3 | 1.54 | 66.0 | – | – |
| 火红TTS | 0.5B | ✅ | 3.82 | 46.0 | 1.51 | 63.5 | 17.45 | 62.1 |
| 火红TTS-2 | 1.5乙 | ✅ | 1.95 | 66.5 | 1.14 | 73.6 | – | – |
| Qwen2.5-全向 | 7乙 | ✅ | 2.72 | 63.2 | 1.70 | 75.2 | 7.97 | 74.7 |
| 开放音频-s1-迷你 | 0.5B | ✅ | 1.94 | 55.0 | 1.18 | 68.5 | – | – |
| 索引TTS2 | 1.5乙 | ✅ | 2.23 | 70.6 | 1.03 | 76.5 | – | – |
| 氛围之声 | 1.5乙 | ✅ | 3.04 | 68.9 | 1.16 | 74.4 | – | – |
| 希格斯音频-v2 | 3乙 | ✅ | 2.44 | 67.7 | 1.50 | 74.0 | – | – |
| VoxCPM | 0.5B | ✅ | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
CV3-eval 基准测试
| 型 | zh | zh | 硬-zh | 硬EN | ||||
|---|---|---|---|---|---|---|---|---|
| CER/% ⬇ | WER/% ⬇ | CER/% ⬇ | SIM卡/% ⬆ | DNSMOS⬆系统 | WER/% ⬇ | SIM卡/% ⬆ | DNSMOS⬆系统 | |
| F5-TTS系统 | 5.47 | 8.90 | – | – | – | – | – | – |
| 火花TTS | 5.15 | 11.0 | – | – | – | – | – | – |
| GPT-SoVits | 7.34 | 12.5 | – | – | – | – | – | – |
| 舒适之声2 | 4.08 | 6.32 | 12.58 | 72.6 | 3.81 | 11.96 | 66.7 | 3.95 |
| 开放音频-s1-迷你 | 4.00 | 5.54 | 18.1 | 58.2 | 3.77 | 12.4 | 55.7 | 3.89 |
| 索引TTS2 | 3.58 | 4.45 | 12.8 | 74.6 | 3.65 | – | – | – |
| 希格斯音频-v2 | 9.54 | 7.89 | 41.0 | 60.2 | 3.39 | 10.3 | 61.8 | 3.68 |
| 舒适语音3-0.5B | 3.89 | 5.24 | 14.15 | 78.6 | 3.75 | 9.04 | 75.9 | 3.92 |
| 舒适语音3-1.5B | 3.91 | 4.99 | 9.77 | 78.5 | 3.79 | 10.55 | 76.1 | 3.95 |
| VoxCPM | 3.40 | 4.04 | 12.9 | 66.1 | 3.59 | 7.89 | 64.3 | 3.74 |
⚠️风险和局限性
- 一般模型行为:虽然 VoxCPM 已在大规模数据集上进行了训练,但它仍可能产生意外、有偏见或包含伪影的输出。
- 滥用语音克隆的可能性:VoxCPM 强大的零样本语音克隆功能可以生成高度逼真的合成语音。该技术可能会被滥用于创建令人信服的深度伪造品,以冒充、欺诈或传播虚假信息。该模型的用户不得使用它来创建侵犯个人权利的内容。严禁将 VoxCPM 用于任何非法或不道德的目的。我们强烈建议使用此模型生成的任何公开共享内容都明确标记为 AI 生成。
- 当前的技术限制:虽然总体上稳定,但模型偶尔可能会表现出不稳定,尤其是在输入非常长或富有表现力的情况下。此外,当前版本对特定语音属性(如情感或说话风格)提供有限的直接控制。
- 双语模型:VoxCPM 主要针对中文和英文数据进行训练。无法保证其他语言的性能,可能会导致音频不可预测或质量低劣。
- 该模型仅用于研发目的。我们不建议在没有严格测试和安全评估的情况下将其用于生产或商业应用。请负责任地使用 VoxCPM。

没有回复内容